

How Salesforce Uses Data Cloud To Solve Its Customers’ AI Last Mile Problem

I have talked extensively about how data, information architecture, and process reengineering are critical for AI agent success. Salesforce is helping me support that story with details from its customer implementations and internal learnings. You’d think the story of Agentforce centered on AI, but the reason it’s seeing success where others are struggling has more to do with Data Cloud than anything else. Thanks to Salesforce’s sponsorship, this article is free for everyone.
The AI Last Mile Problem Has First Mile Solutions
There’s increasing evidence that AI and agents work, but not every business is realizing the same success. I have conducted close to 100 interviews with business leaders and teams that were on the frontlines of agentic failures. I expected to hear stories of how the agents and AI platforms didn’t work. However, the root causes for failure have more to do with data, user adoption, and integration best practices.
That completely changed my approach to agents and AI implementations, but my client success stories are hidden behind NDAs. Salesforce has dozens of customer success stories backing up Agentforce’s ROI and thousands of agents deployed, so the question is…how? What is Salesforce doing to make agents work in real-world product deployments?
Data Governance For Agent-Use Case Alignment
Scaling Data Across The Enterprise
Right-Time Data Aligned With Use Cases
A 360 View Of High-Value Entities
After talking with three Salesforce executives, it’s clear that Data Cloud is a core component of Agentforce’s success, and that tracks with my experience. AI and agents aren’t stand-alone technologies. They cannot succeed without supporting pieces, and data is the most critical. As LLMs are increasingly commoditized, data and information are stepping forward as competitive advantages.
The intelligent core of every firm runs on information, and agents can’t succeed without it. The purpose of Data Cloud is to provide agents with the information required to perceive customer intent, reason about its recommendations, plan the next step or interaction, and act while remaining aligned with reality and the customer’s desired outcome.
What we’re seeing is another example of the AI Last Mile Problem. Businesses face significant challenges in successfully delivering and integrating AI into real-world products and operations to generate quantifiable value. While the symptoms appear at the last mile, the root causes come from first-mile problems, and data is one of the most significant.
Data Governance & Agentic Guardrails
Everyone talks about how access to data helps ensure AI agents deliver responses that are grounded in reality. No one explains how critical and challenging the data governance aspects are. A lack of proper data governance can hinder the scalability of AI use cases over time. It's essential not to "feed the agent with all kinds of data junk."
AI agents can be "pretty smart" and potentially access all available data. But SHOULD THEY? Agentic governance has a lot to do with data governance and setting up appropriate access controls. I implement policies that strictly define the intents that agents are allowed to serve, but given too much data access, that control may not be enough to align agents.
Managing security, governance, and access for these agents is essential for implementing deterministic guardrails. Data Cloud simplifies this through attribute-based access control. It allows agent administrators to ensure that agents have selective information access that they can manage with defined policies and data tagging.
Data governance must support data tagging and classification (PII, PCI, external, internal, etc.), and much of the initial tagging effort must be automated. In Data Cloud, policies can be defined based on these tags, and access is enforced at granular levels like field, row, or object security during agent runtime.
Salesforce recently launched a new data governance capability in Data Cloud that focuses on consistent enforcement through tagging, classification, propagation of tags, and the definition of policies. This capability is critical as businesses move from anonymous to known users and need to manage increasingly complex data security and access challenges.
Scaling Information: The Secret To Agentic Success
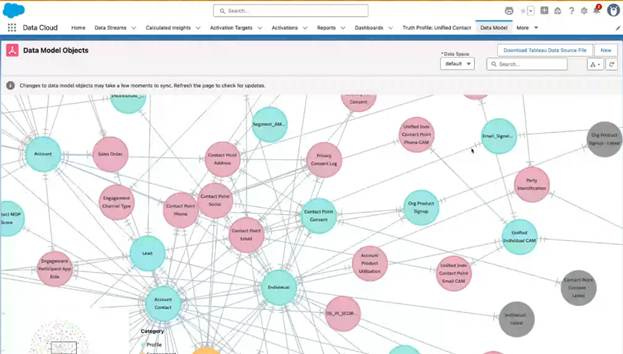
This is a capture from a live production system that Rahul Auradkar, EVP & GM of Salesforce Data Cloud, showed me last week. Enterprise knowledge graphs run behind the scenes at thousands of businesses. Look at the bottom left corner of this image, and you’ll see that we’re only looking at a small region in a much larger graph. It has 1985 segments from 786 data streams. If you want to scale AI and agents, the business must first scale information.
According to Gabrielle Tao, SVP, Product Management at Salesforce, the secrets to managing the cost of scaling information and agents are:
Zero Copy - Eliminate unnecessary data movements and transforms.
Single source of truth that draws from multiple data silos can be achieved via intelligent federation.
Do it once, not once per use case or agent, to future-proof implementations.
Metadata is very important for re-usability, federation, and governance.
The AI and agentic last-mile problem (deploying them to production, improving reliability, scaling, and adoption) is an information first-mile problem. Rahul Auradkar said something interesting: “Data silos are necessary.” Data exists in multiple systems out of necessity, and the multi-application enterprise platform is a reality that information management systems must deal with.
Success requires information architecture to meet the business where it is and work within its existing data architectural patterns. Accelerating time to value requires an approach that avoids forklifts and complex migrations. Getting to the agentic maturity level faster requires an approach to knowledge graph engineering that integrates with what’s in place today.

The Data Cloud approach to developing knowledge graphs is well visualized here. On the left is the business’s data source definitions. Those are mapped to a structured vocabulary of terms in Data Cloud to create a single unified view. Zero Copy facilitates complex metadata mappings with simple interfaces. On the left is the business’s data source definitions. Those are mapped to a structured vocabulary of terms in Data Cloud.
Data Cloud creates an open, unified metadata catalog that’s enriched by AI rather than built by hand. It’s a centralized metadata catalog that enables decentralized (federated) query and access without centralizing the data into a single database. That’s a fundamental value that Data Cloud provides. Its knowledge graph unlocks the value trapped in data while keeping the level of effort low enough to be feasible.
Adopting Information & AI Maturity Is A Human-First Process
What gives data its value? The ability to connect business and customer goals with outcomes. However, it doesn’t go directly to agents from here.
The first step in scaling information for agents and AI is scaling information to be used by people. Agents can’t tell us what data is valuable in the same way experts can. AI doesn’t have an expert’s freedom of action or the ability to generalize that information to deliver new outcomes.
Delivering information to experts creates the short-term ROI while accelerating the journey to agents and AI. Using the maturity models, step 1 is integrating data into processes and workflows. Once internal users and customers trust the data, they are ready for agents and AI to enter the picture. Trust is built incrementally, and autonomy should only be given to agents when they’re reliable enough to meet the requirements of real-world scenarios.
Who better to evaluate that than experts? At step 1, the business gets to assess how reliable and valuable its data is. If experts can’t use it to connect business and customer goals with outcomes, agents won’t be able to either. If expert outcomes don’t improve, the agents won’t either.
Once experts have run the first phase of information improvement cycles, AI agents have a clear information space defined. Experts validate that the right information is delivered at the right time to improve outcomes. Salesforce uses a much cooler term for providing the right insights at the point of impact: ‘Data Fluidity’.
A Unified 360 View Of High-Value Entities
Mapping data from multiple silos enables a 360 view of complex, high-value entities. Most enterprises have 3 different definitions of a sale. There are dozens of customer and supplier views. Sales, customers, products, suppliers, and many other entities have high visibility within each silo, but low HOLISTIC transparency (aggregating data from multiple sources) and low transparency across business units (distributing information from one silo to another).
Understanding an entity holistically creates value by improving decisions and their business outcomes. Rahul Auradkar provided a real-world example. Imagine you have a baseball card with your customer’s most important statistics.
Put this in the hands of a luxury brand’s sales associates. Customers walk into the store, and the associate gets their baseball card on a tablet. With information about prior purchases and preferences, they’re able to provide a concierge-level of service and personalized recommendations.
Put a new supplier’s baseball card into the hands of the team negotiating pricing on a large order. Information is power in pricing conversations.
The key to value creation is targeting decisions to optimize for an outcome with people first. Now put that customer baseball card in the hands of an AI agent. Experiences that were only possible in-store get replicated on the website and in the app. Concierge service levels online become a competitive advantage.
Businesses now compete on best-in-class capabilities. The ability to deliver a 360 view of the customer to sales associates enables personalization and higher service levels. Delivering it to agents brings that best-in-class capability into the digital space. Both reset customer expectations. Competitors without those technical capabilities can’t duplicate the customer experience and fall behind.
Right-Time Data Aligned With Use Cases
Most businesses focus on real-time data, but part of the ‘Data Fluidity’ paradigm is the concept of right-time data. That aligns information and insights with the use case and delivers them at the point of value creation.
Only a few use cases truly require real-time (sub-second) information delivery. Rahul Auradkar talked about website personalization as one example. A customer shows up on the website, and there’s no information about them, so they are served a generic landing page. The customer searches for jackets, views one, then returns to the homepage. Without real-time data, that’s still a generic landing page.
However, the customer has revealed their intent: shopping for a jacket. Businesses that can create a new customer record based on this single session and customize the homepage with that intent will get more customers to buy. For this personalization use case, real-time data is worth the cost.
Now, think about agentic workflows where response latency is a huge issue. Most agentic workflows require sub-second real-time data or access to data with sub-second response times. The information layer must deliver both, or agents can’t leverage data to meet customer needs.
For many other use cases, right-time information is a more pragmatic paradigm than streaming everything in real-time. It takes a deep understanding of the process or workflow being supported to define the information requirements. That’s only feasible with the transparency created by a 360 view of complex entities and workflows.
What’s Next? Agentic Adoption
Information is a critical enabler for agents. I referenced agentic adoption and designing for adoption. In my next article in this series, I’ll dig into real-world examples of enterprise agentic adoption. Salesforce takes a customer 0 approach, which means its internal teams are the first customers for most new products, and Agentforce is no exception.
What is the level of difficulty to do the initial tagging and classification?
Is it the amount of data or size of company or complexity of the industry or access permissions that are the variables or something else altogether?
Few companies seem to have a data governance policy - much less an organization-wide one. And not all companies seem to have a chief data architect or even chief systems architect. Investment banks and other financial services companies.
Data has been cobbled together over decades and continued to append without labeling/organizing/ontology across disparate systems, geographies with different data privacy rules, and in terms with high turnover where institutional knowledge was lost.
Thank you for writing this comprehensive article!
Now I know that their Data Cloud functions as the "Context Layer" cloud version, which makes a lot of sense. Agents need access to this context layer to execute, so this is the communication layer the service needs.
I'm thinking that depending on the date-storage solutions companies employ, those providers may offer different solutions to this high-level context. If that is not easily available, or it requires additional transformations, it creates a barrier to adoption.
If the data-storage providers are exploring their own agentic solutions, their monetizing strategy won't include making it easy to use a different context layer provider.
Platform distribution problem.