

Watsonx: Is IBM's Generative AI And Foundational Models Platform The Future Or More Like The Watson Of The Past?

IBM is not known for being on the leading edge of technology, and that's why its clients love the company. In the move fast and break things culture that dominates so much of the AI conversation, they are a move slow and fix things kind of company. The last time I worked with IBM was in 2017.
The culture back then was a contradiction, older and very optimistic. This time around was different. IBM is still a contradiction, younger and very pragmatic. Some of IBM's team walked around IBM Think wearing blue and white custom Nike's with the IBM logo on the back. As a sneakerhead, I was a little jealous.
When I talked with product team members, they showed a laser focus on use cases, customer needs, and practical applications. I suggested a more innovative alternative to how they approached the data lakehouse and got yelled at. They refused to be distracted.
IBM has become a business focused on how AI will work in the real world. They are meeting customers and clients where they are, not where IBM wants them to be. When a business is dialed into its customers, the product team gets angry when anyone implies they are disconnected from customer needs.
Won't Get Fooled Again
IBM's watsonx platform is impressive, but not in any of the ways most of us are used to being impressed. I spent the last week at IBM Think 2023 and got an advanced preview of what's next for Big Blue. This is not your grandpa's Watson, but it's not OpenAI's either.
To be clear, IBM is not an innovator in the Silicon Valley startup sense. And that's a good thing for most businesses. Vinod Khosla, founder of the VC firm Khosla Ventures, recently said that 90% of AI startups will fail. That's similar to the outcome of Web3's recent hype cycle and bust. Business leaders don't want any part of that style of speculative tech, and most look at Generative AI as history repeating itself.
IBM once tried to be that hybrid startup-incumbent with a legacy business customer base on the bleeding edge of technology innovation. I'll bet you didn't know that IBM was an early adopter of blockchain. They shut down that business unit two years ago. It was another example of technology in search of use cases.
In 2010, Watson was released with a lot of hype and fanfare. For me, it was one of the signs that data science was coming into its own. I jumped into the field headfirst. Watson turned out to be a very impressive demo, but not ready for prime-time. Even though it did beat several Jeopardy contestants on prime-time TV, 2010's version of going viral on social media. GPT has inspired many impressive demos. We're going through a similar hype cycle, but it's at scale this time.
IBM announced a partnership with Hugging Face on the first day of the conference. I thought they were just name-dropping and playing into the hype around Hugging Face. When Clem Delague, Hugging Face's CEO, came out for the closing keynote, it became obvious that this is a deeper partnership.

Clem said the IBM + Red Hat partnership was one of the biggest of the last decade, and he hoped the IBM + Hugging Face partnership would be even bigger for AI. He talked about how IBM and Hugging Face share many of the same values. Coming out on stage to pitch the partnership was expected, but endorsing IBM's open source creds is something different altogether. Time will tell, but this looks like a genuine partnership.
Tough Lessons Lead To High-Value Products
It looks like IBM has learned a lot from the first Watson experiment. Today, Khosla's "90% of AI startups" segment is a few months away from repeating the first Watson's mistakes. Going into Think 2023, I believed that keeping the Watson name was a bold move to put it kindly. The brand has so much baggage, but IBM owns those mistakes and wears them like a badge of honor.
I'm not the only one saying IBM made mistakes with the original Watson. In the AMA I attended this week with IBM Chairman and CEO Arvind Krishna, he admitted them openly. The first version of Watson was a failed experiment. They made many mistakes, and he talked about how lessons learned have built watsonx.
Machine learning & deep learning are tough to monetize. Models don't generalize well, so they must be built use case by use case. Foundational models are different.
This time, IBM's leading with a developer's platform and opening up to data scientists. That was a major omission in the original platform.
Transformers allow customers to get to value faster by not needing expensive labeled data sets. A lower-cost, more accessible approach will drive adoption.
Productivity will be IBM's primary use case. Working with enterprise vs. consumer-facing use cases fits IBM's market & competitive advantages better.
IBM is customer 1 for everything they develop. They're learning to help customers by being the first customer.
IBM is demystifying the technology rather than making it a black box they control. They want to make foundational models more accessible and practical for business use cases.
Horizontal scale vs. vertical. Foundational models provide functionality across industries. Watson's mistake was trying to scale vertically and get deep into each industry.
IBM is focused on narrow use cases with proprietary data vs. broad functionality with low reliability.
Ecosystem approach. IBM allows customers to bring their own models, build new models, use IBM's foundational models, or leverage open-source models on the watsonx platform. They've integrated with partners like SAP.
Supporting customers with client engineers and data scientists. IBM can take clients from 0 to deployment on watsonx and teach clients how to maximize the technology. IBM is building a consulting CoE for generative AI.
To move on from a Watson-style failure, it's imperative that a business admits what went wrong and begins to talk about what it's learned. It seems like IBM spent time doing a tough introspection and decided to keep the Watson brand alive. However, watsonx is a completely different product than the first version. The focus and utility are entirely new.
Rebuilding A Mature, Product Focused AI Platform
Over the last three years, IBM has rebuilt Watson into a product the market wants. This release is extremely compelling because of IBM's honesty, transparency about mistakes made, and laser focus on customer needs. I got a few demos and saw exactly what the new watsonx is.
Their lessons learned are on full display. IBM is making a quiet comparison between the immature hype cycle-driven products built on generative AI and watsonx. No one at IBM said it out loud this week, but the message was unmistakable. "We made the mistakes you see startups repeating today over a decade ago. We put what we learned into practice in watsonx."
Watsonx has three modules. The first one is a data science development studio, watsonx.ai. It allows businesses to access a range of foundational models. IBM, like many others, is looking at generative AI as a starting point, not the destination. In its development studio, IBM makes accessing its suite of foundational models easy. IBM's cleverly named them after different types of bedrock. Get it? Foundational models built on IBM's bedrock.
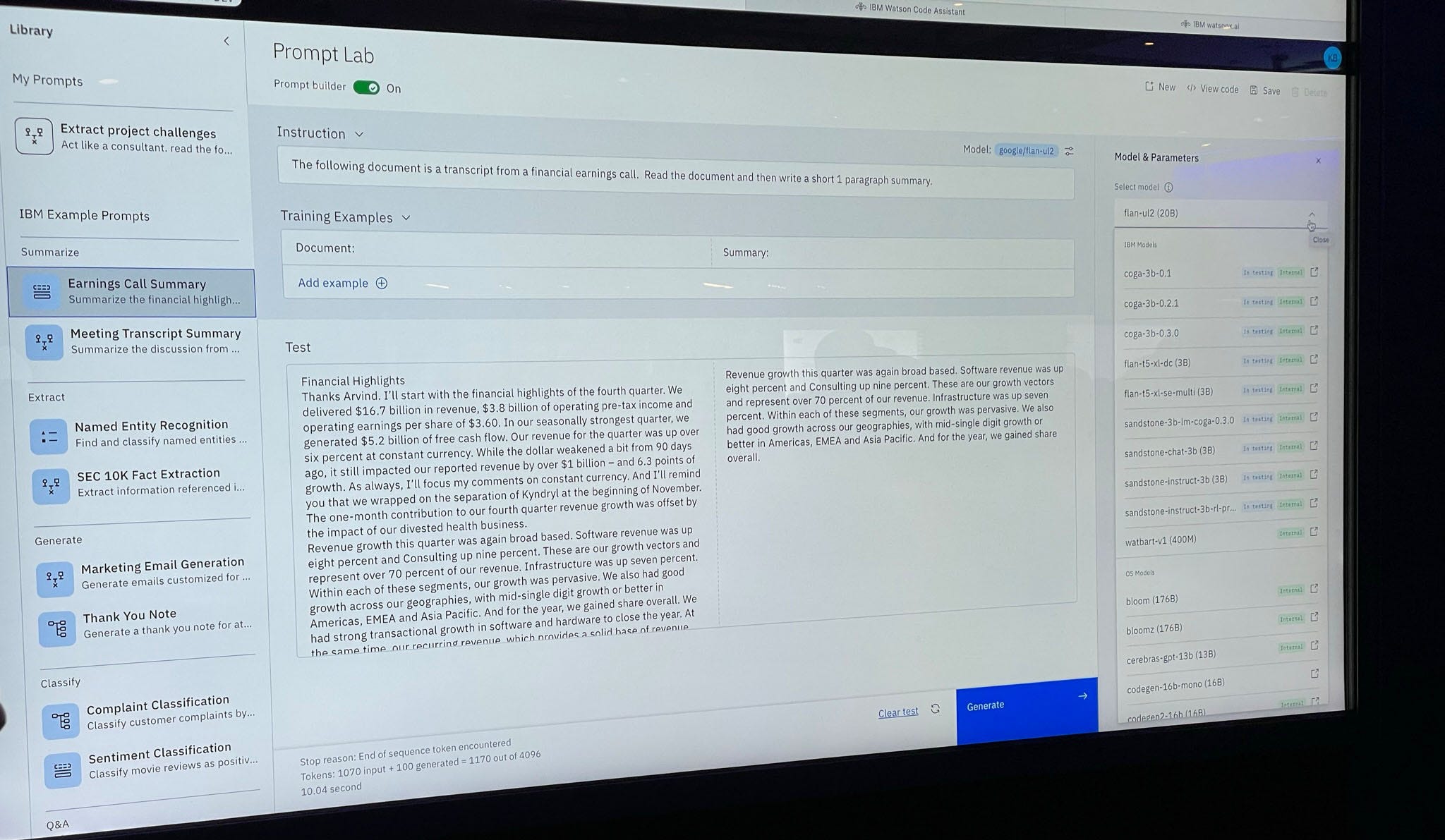
It's more than clever marketing. IBM doesn't intend its models to be the end state for enterprise apps and AI products. It wants customers to build on top of what IBM considers strong foundations. The company doesn't believe one-size foundational models will fit all customer needs.
That's where the partnership with Hugging Face comes into play. Hugging Face hosts over 100K generative models. Innovation on the Hugging Face platform is moving incredibly fast, with 4000 models added the week before the conference alone. IBM understands it would be too expensive to keep up with the state-of-the-art marathon. There's no way for a business to win that battle. IBM has chosen a smart strategy that brings its customers the best of both worlds.
The pace of improvement is so fast that it prompted Google to claim it has no moat. IBM's CEO was asked about that famous quote. He said that technology has never been a moat on its own. Again, Watson's lessons came through. He described different competitive advantages and moats.
The first was the most compelling. Customers trust IBM to keep their data safe. He cited examples and said that no one asks IBM to put data privacy language into its contracts. Trust has been built by IBM's track record.
Others in the generative AI space cannot say the same. Google's latest PaLM 2 model is impressive, but it will soon be copied, optimized, and improved upon by the open-source community. More than that, Google's record with data security makes it perilous to implement its models for enterprise applications. Microsoft's use of GitHub data for GPT training has brought its track record on data privacy into question too.
The list of shady use of data for training large models could be the focus of an entire article. Suffice it to say that enterprises have few options if they want to use generative AI and maintain control over their proprietary data.
Rebuilding Foundational Models With Proprietary Data
IBM's customers aren't locked into its set of foundational models. Through watsonx, customers can access the complete open-source ecosystem of Hugging Face models and bring their own models too. Customers can rebuild from any of those baseline foundational models with their own data. IBM explains that this is the competitive advantage businesses are looking for. Data is a major differentiator.
Under the covers, the original model's weights don't change. Foundational models are appended with the new weights learned from the training data set. IBM doesn't believe that foundational models are accurate enough for businesses to apply straight out of the box. They're not wrong because, in application after application, we see the negative impacts of hallucination.
For business critical or customer-facing applications, hallucination's impacts are enough to keep businesses from adopting foundational models like GPT. What's taken consumers by storm isn't reliable enough for enterprise use cases. That's the gap IBM is building watsonx to fill.
With watsonx, IBM has made the process simple. Setting up and kicking off the training job takes less than 30 minutes. I've worked with clients to set up stand-alone Azure instances of generative models, and it takes a lot longer than that. AWS's toolset isn't anywhere near as intuitive as IBM's.
IBM made a clear distinction between consumer and enterprise applications. The company believes consumer applications play by a far looser set of rules. As a result, some of the solutions that are ready for consumers are not ready for internal enterprise use cases. I think they're right about that, too.
As I drove from the airport to the conference, I was struck by how many billboards advertised personal injury attorneys. The claims of massive settlements are attractive, but anyone with common sense knows there's a scam hiding behind most. Enterprise apps using generative AI have a lot in common with those billboards. IBM is offering a more trusted alternative.
IBM has also recognized that applying a single model to a range of use cases isn't feasible. Again, it's a matter of functionality. Even retraining with the business's internal data won't overcome broad challenges and provide functionality across a range of use cases.
To handle this, IBM has focused on specific use cases. Retraining models is meant to serve specific workflows. Instead of handling everything for every part of the business, the foundational model is retrained with a workflow in mind. Watsonx is designed to make this easy to do from end to end.
Supporting Data Curation And AI Governance
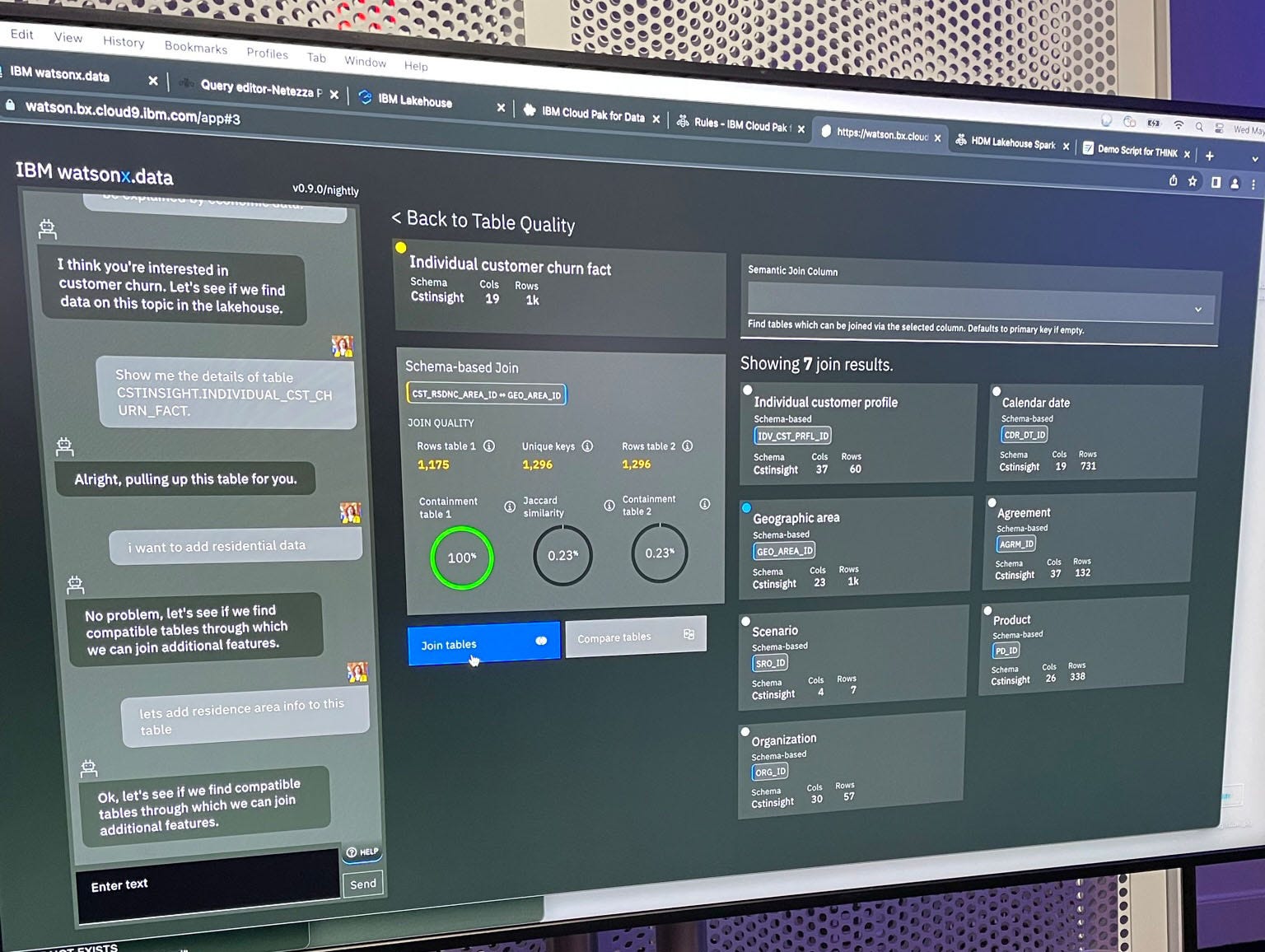
The other two components of watsonx facilitate enterprise use cases. Watsonx.data is IBM's new lake house solution. It allows data ingestion from multiple engines. That’s a big deal on its own, but it also makes discovering data much easier.
One of the most complex tasks a data analyst gets is figuring out what data should be used and where that data lives. In many companies, it requires data analysts and data engineers to find domain experts who can interpret what each data set contains. There's also the complexity of translating field names into something that makes sense outside of that organizational silo.
The data lakehouse allows users to query with natural language. The user was asking for location demographics data in the demo I watched. Watsonx.data could return multiple data sets that fit the query. What's more, instead of just providing the generic column headers, it could pull from the data catalog. It used the information from the data catalog to enrich and augment the descriptions for each column in the data set.
Users are also able to drag and drop from parquet or CSV files. Watsonx.data provides users with an easy way to import data from the lake house, files, SQL queries, or to augment from other internal data sources.
Watsonx.governance allows the business to understand the bias and the problems that go along with foundational models. In IBM's words, it "helps bring light into the black box." Watsonx.governance allows the business to monitor, manage, and govern models at scale.
It's designed with a simple workflow/lifecycle view covering metadata capture and retraining recommendations. Watsonx.governance is intended to help the business identify risk and remain compliant with the rapidly changing regulatory landscape. The dashboard gives stakeholders transparency into how well their models perform in production. It allows the data team to automate some audit and compliance work.
Without both components, the watsonx.ai piece could not service enterprise use cases. Streamlining data engineering, data discovery, model monitoring, and model governance is critical backend functionality. Most platforms that I've seen ignore those parts of the workflow. They aren't very glamorous, but they are critical for businesses to productize and commercialize AI models, even for internal-facing use cases.
What's Next?
Watsonx will be in a beta release for another couple of months. It doesn't feel finished yet. I tried to get an idea of what's on the roadmap, but IBM is being very cautious about what they disclose. It's not out of secrecy. IBM's focus is on what customers can use and build with today.
That's another lesson learned from the first Watson. Instead of discussing what's coming and possible, IBM stays close to what's available and ready to use now. That's what business leaders are most interested in. Most of my clients are looking to cash in on generative AI's productivity promise before moving on to develop customer-facing products.
Cathie Wood, CEO of Arc Invest, says, "the killer app for AI is productivity gains." She shares IBM's view that proprietary data and domain expertise will decide which businesses will succeed with generative AI. Cathie Wood and IBM's CEO call out AI expertise as a third critical success factor.
Over the next several months, IBM will build a Center of Excellence (CoE) for foundational models and generative AI. It's a new branch of IBM Consulting’s business. The goal is to accelerate AI adoption and transformation. Most companies don't have the people in place to ramp up quickly. IBM's new CoE will fill that gap and bring these solutions to customers no matter where on the maturity scale they are. That's good news because most businesses are behind on their transformation journeys.
It's unlikely that IBM will ever be seen as a company on the leading edge of technology. Watsonx is built on incremental innovations and functional improvements. It's not light years ahead of generative AI startups, but it's years ahead of where IBM's customers are today. It is built for where IBM's customers need to be to remain competitive. The focus is pragmatic and centered on high-value use cases.
This isn't what the generative AI hype cycle is trying to get us all to focus on. For IBM's customers, it's what they should focus on and what will deliver the most value in the shortest time.
IBM partners with industry thought leaders like me to share our opinions and insights on current technology trends. I attended Think 2023 as IBM’s guest, and the opinions in this article are my own and do not necessarily reflect the views or strategies of IBM.
Thanks for the analysis of Watsonx Vin. Especially interested in the enterprise applications of this improved AI platform, and the AI governance module, to monitor, guide, and govern AI models in production, at enterprise scale. I really like how IBM integrates its products seamlessly, and is intuitive to the customer. Sounds like it will continue this experience for the client. Bravo 👏